Rapid advances in analytical modelling and information processing capabilities, particularly in machine learning (ML) and artificial intelligence (AI), combined with ever more granular data are currently transforming many aspects of everyday life and work. In this blog post we give a brief overview of basic concepts of ML and potential applications at central banks based on our research. We demonstrate how an artificial neural network (NN) can be used for inflation forecasting which lies at the heart of modern central banking. We show how its structure can help to understand model reactions. The NN generally outperforms more conventional models. However, it struggles to cope with the unseen post-crises situation which highlights the care needed when considering new modelling approaches.
Similarly to the victory of DeepBlue over chess world champion Garry Kasparov in 1997, the 2017 victory of AlphaGo over Go world champion Ke Jie is seen as a hallmark of the advancements of machine intelligence. Both victories were made possible by rapid advancements of information technologies, however in different ways. For DeepBlue, it was improvements in computer memory and processing speed. But for AlphaGo, it was the ability to learn from and make decisions based on rich data sources, flexible models and clever algorithms.
Recent years have seen an explosion in the amount and variety of digitally available data (“big data”). Examples are online activities, such as online retail and social media or from the usage of smartphone apps. Another novel source is the interaction of the gadgets themselves, e.g. data from a multitude of sensors and the connections of everyday devices to the internet (the “internet of things”).
Monetary policy decisions, the supervision of financial institutions and the gauging of financial market conditions – the common tasks of the Bank of England and many other central banks – are certainly data-driven activities. However, these have traditionally been fuelled by relatively “small data”, often in the form of monthly or quarterly time series. This also changed in recent years, partly driven by reforms following the Global Financial Crisis 2008 (GFC), which handed central banks and regulators with additional powers, responsibilities and more data. These novel data sources and analytical techniques provide central banks, and also the economics profession more widely, with new opportunities to gain insights and ultimately promote the public good.
What is machine learning?
ML is a branch of applied statistics largely originating from computer science. It combines elements of statistical modelling, pattern recognitions and algorithm design. Its name can be interpreted as designing systems for automated or assisted decision making, but not (yet) autonomous robots in most cases. Hence, ML is not a fixed model or technique, but rather an analytical toolbox for data analysis, which can be used to tailor solutions for particular problems.
The main difference between ML and conventional statistical analysis used in economic and financial studies (often summarised under the umbrella of econometrics) is its larger focus on prediction compared to causal inference. Because of this, machine learning models are not evaluated on the basis of statistical tests, but on their out-of-sample prediction performance, i.e., how the model describes situations it hasn’t seen before. A drawback of this approach is that one may struggle to explain why a model is doing what it does, commonly known as the black box criticism.
The general data-driven problem consists of a question and a related dataset. For example, “What best describes inflation given a set of macroeconomic time series?” This can be framed as a so-called supervised problem in ML terminology. Here, we are trying to model a concrete output or target variable Y (inflation), given some input variables X. These supervised problems can be further segmented into regression and classification problems. The regression problem involves a continuous target variable, such as the value of inflation over a certain period of time. Classification, in the other hand, involves discrete targets, e.g. if inflation is below or above target at certain point in time, or if a bank is in distress or not. Alongside this, there is also unsupervised machine learning where no such labelled target variable Y exists. In this case, any ML approach would try to uncover an underlying clustering structure or relationships within data. These main categories of machine learning problems are shown in Figure 1. We discuss a case study for all three problem types in SWP 674: Machine learning at central banks. Case study 3 on analysis tech start-ups with a focus on financial technology (fintech) is also reviewed in this post.
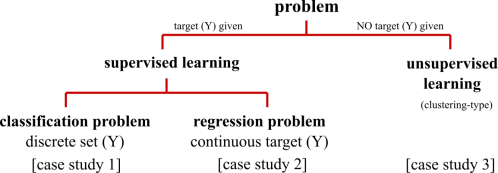
Figure 1: Machine learning taxonomy. Case studies refer to SWP 674: Machine learning at central banks.
Case study: UK CPI inflation forecasting
As a simple example, we feed a set of macroeconomic time series (e.g. the unemployment rate or rate of money creation) into an artificial neural network to forecast UK CPI inflation over a medium-term horizon of two years and compare its performance to a vector autoregressive model with one lag (VAR). It is worth noting that this is not how central banks typically forecast inflation but it works well to see how ML techniques can be used.
An important aspect to consider here is that many ML approaches do not take time into account, meaning that they mostly focus on so-called cross sectional analyses. ML approaches which do take time into account are, among others, online learning or reinforcement learning. These approaches would need considerably more data than are available for our coarse-grained time series. We therefore take a different approach building temporal dependencies implicitly into our models. Namely, we match pattern in a lead-lag setting where changes in consumer prices lead changes or levels of other aggregates by two years. The contemporaneous 2-year changes of input variables and CPI target are shown in Figure 2, with the exception of the Bank rate, implied inflation from indexed Gilts and the unemployment level which are in levels. One can see that the crisis in the end of 2008 (vertical dashed line) represents a break for may series.

Figure 2: Selection of macroeconomic time series used as inputs and target of NN.
A key element of machine learning is training, i.e. fitting, and testing a model on different parts of a dataset. The reason for this is the mentioned absence of general statistical tests in many situations. The difference between training and test performance indicates then how well a model generalises to unseen situations. In the current setting this is performed within an expanding window setting where we successively fit the model on past data, evaluate its performance based on an unconditional forecast and then expand the training dataset by a quarter.
The result of this exercise is given in Figure 3, which shows the model output of a neural network (NN) with two hidden layers, technically a deep multi-layered perceptron. This is a multi-stage model which combines weighted input data in successive layers and map these to a target variable (supervised learning). They are also at the forefront of recent AI developments. The NN model (green) in this unconditional forecast has an average annualised absolute error below half a percentage point over a two-year horizon during the pre-GFC period. This is already more than twice as accurate as the simple vector-autoregressive (VAR) benchmark model with one lag (grey line in Figure 3). The NN also shows relatively low volatility in its output, contrasted to the VAR.

Figure 3: ML model performance of combination of a deep neural network and support vector machine (green) relative to UK CPI inflation (blue). Red prediction intervals (PI) are constructed from sampled input data. The GFC only impacts the models in 2010 because of 2-year lead-lag relation of all models. Source: SWP 674.
Looking into the black box
ML models, particularly deep neural networks, are often criticised for being hard to understand in terms of their input-output relations. We can, however, get a basic understanding of the model in the current case as it is relatively simple. The model performance in Figure 3 drops markedly as soon as the effects from the GFC enter the model (vertical red dashed line), forecasting inflation persistently too low.
This behaviour can be understood when looking at the NN input structure before and after the GFC. Figure 4 depicts the relative weights stemming from different variables entering the first hidden layer of the neural network for pre and post-crisis data. This part of the NN has been identified to contribute the leading signal of the model’s output. We see that changes in private sector debt and gross disposable household income (GDHI) provided the strongest signal in the pre-crisis period, as seen by the darker shades of normalised inputs. Particularly, the former saw a sharp drop at the onset of the crisis. Post-crisis, model weights gradually gave more importance to the increased level of unemployment. Both factors can explain why the neural network – wrongly in this case – predicted a sharp drop in inflation (see Figure 2).
The above discussion can best be thought of as a statistical decomposition. Artificial neural networks, like other machine learning approaches, are non-structural models focusing on correlations in the data. Therefore, care has to be given when interpreting the results of such an analysis. A strong correlation may or may not point to a causal relationship. Further analyses may be needed to pinpoint such a relation.
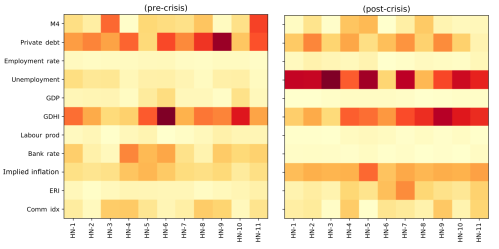
Figure 4: Pre and post crisis input weight structure to first (hidden) layer of neural network from macroeconomic time series inputs. Darker values indicate a stronger signal. Source: SWP 674.
Conclusion
We have given a very brief introduction of machine learning techniques and demonstrated how they might be used for tasks which central banks have been trusted with. Many of these tasks are linked to the availability of ever more granular data. Here, their particular strength lies in the modelling of non-linearities and accurate prediction.
However, care is needed when interpreting the outputs from ML models. For example, they do not necessary identify economic causation. The fact that a correlation between two variables has been observed in the past does not mean it will hold in the future, as we have seen in the case of the artificial neural network when it is faced with a situation not previously seen in the data, resulting in forecasts wide of the mark.
Note: Bank Underground is a blog for Bank of England staff to share views that challenge – or support – prevailing policy orthodoxies. The views expressed here are those of the authors, and are not necessarily those of the Bank of England, or its policy committees.







